[ELK] 13. kibana 살펴보기
Kibana
2022.06.21 - [ELK stack] - [ELK] 1. Elastic Stack
[ELK] 1. Elastic Stack
필자는 파이썬(python, numpy, pandas, matplotlib, plotly)을 활용한 데이터 전처리, 피처 엔지니어링, 모델링을 진행한 경험이 다수 있지만, 서비스 단계에서 사용하는 데이터 파이프라인은 경험해보지 못
wnstjrdl.tistory.com
kibana를 실행하면 아래와 같은 화면이 나오는데, 이것은 메인 화면입니다. 그리고 주로 사용하는 옵션은 왼쪽 상단 드롭 박스의 Analytics > Discover, Dashboard입니다.


이때까지 아파치 로그 데이터를 우리가 원하는 필드 매핑에 맞게 인덱스 재색인 과정을 거쳐 mylogs-{날짜} 형식으로 elasticsearch에 저장했습니다. 그리고 kibana를 통해 시각화하는 것이 목표입니다.
시각화하기 전에 먼저 인덱스 패턴을 만들어줘야 합니다.
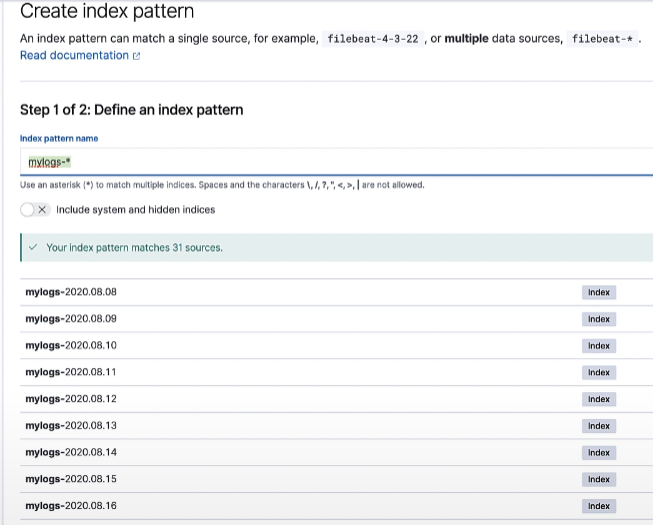
일반적으로 인덱스 패턴을 만드는 방법은 Management > Stack Management를 누르면 왼쪽 Kibana > Index Pattern에서 지정할 수 있습니다. 첫 번째 우리가 지정한 mylogs 데이터들을 정해줍니다.
두 번째는 time field를 정해야 하는데 kibana는 기본적으로 시계열 데이터를 가정하고 만들기 때문에 시계열 데이터 필드를 지정해주면 됩니다.

그렇게 만들고 나면 각 필드의 타입과 집계/검색 여부를 파악할 수 있는 테이블을 보여줍니다. 그렇게 인덱스 패턴을 만들면 메인 페이지의 Discover, Dashboard 메뉴에서 분석을 진행하면 됩니다.
Discover는 데이터 조회, 명령문 확인, 리스트 조회 등 데이터를 전반적으로 조회하고 간단하게 보여주는 메뉴입니다.
Dashboard는 조회와 필터링을 거쳐 시각화로 보여주고, 여러 시각화 자료를 한 번에 보여줄 수 있는 메뉴입니다.
각자 실습은 아래 공식문서를 참고하면서 필요한 부분을 발췌하는 식으로 하시면 좋을 거 같습니다.
https://www.elastic.co/guide/en/kibana/current/index.html
Kibana Guide [8.3] | Elastic
www.elastic.co
마무리
이번 포스팅은 ELK stack의 시각화 기능을 담당하는 kibana에 대해 간단하게 알아보았습니다. 시각화 기능은 너무 많아서 소개하지는 않았지만 공식문서에 자세하게 설명이 되어 있으니 참고 부탁드립니다.
ELK 포스팅의 마지막이 되었습니다. 다음 포스팅은 ELK stack을 활용한 프로젝트를 진행할 계획을 가지고 있습니다. 개인적으로 google cloud를 사용하면서 실습들을 진행해왔는데, 과금이 많이 나와서 시급히 끊고 다른 방식을 찾고 있습니다.
이번 기회에 도커도 학습하여 도커 기반으로 ELK stack을 다시 설정하고 할 계획도 있습니다.
부족한 포스팅 잘 봐주셔서 감사합니다.