[SQL로 배우는 데이터 전처리 분석] 6. 상품 리뷰 데이터를 이용한 리포트 작성 (1) - Division별 평점 분포 계산
천 대리님, 의류 회사에서 상품별 리뷰 데이터를 분석해 달라는 요청을 받았습니다. 상품 평점을 통해 상품의 문제점과 개선 방향을 찾는 것이 이 분석의 주요 목적입니다. 천 대리님이 자유롭게 분석해서 공유해 주세요.
이번 포스팅은 상품 리뷰 데이터를 이용하여 Division별 평점 분포를 계산해보겠습니다.
1) Division별 평균 평점 계산
먼저 Division별로 평점을 계산해 보고, 어떤 Division의 상품이 좋은 평가를 받는지 또는 좋지 않은 평가를 받는지 살펴보겠습니다.
해당 데이터 세트의 칼럼 구조를 살펴보겠습니다.

- Clothing ID : 상품 번호 (Unique Value)
- Age : 나이
- Title : 리뷰 제목
- Review Text : 리뷰 내용
- Rating : 리뷰 작성자가 제출한 평점
- Recommended IND : 리뷰어에 대한 상품 추천 여부
- Positive Feedback Counter : 긍정적 피드백 수
- Division Name : 상품이 속한 Division
- Department Name : 상품이 속한 Department
- Class Name : 상품의 타입
a) DIVISION NAME별 평균 평점
Division별 평균 Rating을 계산하려면 먼저 Division Name으로 그룹핑한 뒤, 점수를 평균하는 작업을 실행하겠습니다.
SELECT `DIVISION NAME`,
AVG(RATING) AVG_RATE
FROM MYDATA.DATASET2
GROUP BY 1
ORDER BY 2 DESC;
3개의 DIVISION 모두 유사한 평점을 갖는 것으로 확인되었습니다. DIVISION NAME의 공란은 데이터가 없는 것으로 판단하겠습니다.
b) DEPARTMENT별 평균 평점
SELECT `DEPARTMENT NAME`,
AVG(RATING) AVG_RATE
FROM MYDATA.DATASET2
GROUP BY 1
ORDER BY 2 DESC;
Bottoms부터 상위 5개의 Department는 유사한 평점이 가진 것으로 보입니다. 하지만 Trend는 3.85점으로 상위 대비 평점이 낮게 나옵니다.
Trend에 어떤 문제가 있는지 파악하겠습니다.
먼저 Trend의 좋지 않은 리뷰(평점 3점 이하)의 연령별 분포를 살펴보겠습니다.
쿼리를 작성하기 위해서 DEPARTMENT NAME을 TREND로 한정하고 RATING은 3점 이하의 조건을 추가하면 됩니다.
SELECT *
FROM MYDATA.DATASET2
WHERE `DEPARTMENT NAME` = 'Trend' AND RATING <= 3;
쿼리를 실행하면, RATING이 3점 이하이고 DEPARTMENT NAME은 TREND인 데이터가 모두 조회됩니다.
따라서 위의 데이터 세트에서 연령으로 데이터를 그룹핑하고 카운트로 집계하면, 우리가 원하는 결과를 얻을 수 있습니다.
구간을 그룹으로 나누어 집계하는 방법에는 크게 2가지가 있습니다. (CASE WHEN, FLOOR)
2) CASE WHEN
case when 구문을 사용해 우리가 원하는 그룹을 생성할 수 있습니다. 예를 들어 연령을 10세 단위로 그룹핑을 진행해보겠습니다.
SELECT CASE WHEN AGE BETWEEN 0 AND 9 THEN '0009'
WHEN AGE BETWEEN 10 AND 19 THEN '1019'
WHEN AGE BETWEEN 20 AND 29 THEN '2029'
WHEN AGE BETWEEN 30 AND 39 THEN '3039'
WHEN AGE BETWEEN 40 AND 49 THEN '4049'
WHEN AGE BETWEEN 50 AND 59 THEN '5059'
WHEN AGE BETWEEN 60 AND 69 THEN '6069'
WHEN AGE BETWEEN 70 AND 79 THEN '7079'
WHEN AGE BETWEEN 80 AND 89 THEN '8089'
WHEN AGE BETWEEN 90 AND 99 THEN '9099' END AGEBAND,
AGE
FROM MYDATA.DATASET2
WHERE `DEPARTMENT NAME` = 'Trend' AND RATING <= 3;
AGE와 AGEBAND를 살펴보면, 우리가 의도한 대로 연령대가 생성된 것을 확인할 수 있습니다.
위의 방법은 하나씩 연령 구간을 설정해야 한다는 점에서 번거로움이 있을 수 있습니다.
FLOOR를 사용하면 10세 단위로 연령을 쉽게 나눌 수 있습니다.
3) FLOOR
연령을 10으로 나눈 값을 버림 하면 어떤 값을 얻을 수 있을까요?
예를 들어 23을 10으로 나누면 2.3이라는 값을 얻고 여기서 버림 하면 2가 나오고 10을 곱하면 해당 연령대인 20을 구할 수 있습니다.
이것을 이용해 연령대를 구해보도록 하겠습니다.
SELECT FLOOR(AGE/10)*10 AGEBAND,
AGE
FROM MYDATA.DATASET2
WHERE `DEPARTMENT NAME` = 'Trend' AND RATING <=3;
CASE WHEN을 사용하는 것보다 훨씬 간단한 방법으로 10 단위로 연령을 나눌 수 있게 되었습니다.
그렇다면 이 값으로 데이터를 그룹핑하고 COUNT로 집계한다면, 연령별 리뷰 수를 구할 수 있겠습니다.
a) Trend의 평점 3점 이하 리뷰의 연령 분포
SELECT FLOOR(AGE/10)*10 AGEBAND,
COUNT(*) CNT
FROM MYDATA.DATASET2
WHERE `DEPARTMENT NAME` = 'Trend' AND RATING <= 3
GROUP BY 1
ORDER BY 2 DESC;
50개에서 3점 이하의 평점 수가 많은 것으로 확인됩니다. 하지만 50대가 Trend라는 Department에 가장 많은 불만이 있다고 할 수 있을까요?
만약 Trend의 리뷰 중 50대 리뷰가 압도적으로 많다면, 위 결과는 당연한 결과일 겁니다.
그렇기 때문에 Trend의 전체 연령별 리뷰 수를 구해보아야 합니다.
b) Department별 연령별 리뷰 수
SELECT FLOOR(AGE/10)*10 AGEBAND,
COUNT(*) CNT
FROM MYDATA.DATASET2
WHERE `DEPARTMENT NAME` = 'Trend'
GROUP BY 1
ORDER BY 2 DESC;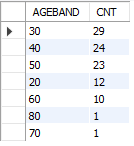
위 결과를 보면 50대의 Trend에 대한 평점이 다소 좋지 않은 것으로 생각할 수 있습니다.
더 명확하게 결과를 확인하기 위하여 50대 3점 이하 Trend 리뷰를 살펴보겠습니다.
c) 50대 3점 이하 Trend 리뷰
SELECT *
FROM MYDATA.DATASET2
WHERE `DEPARTMENT NAME` = 'Trend' AND RATING <=3 AND AGE BETWEEN 50 AND 59 LIMIT 10;
Review Text를 몇 가지 살펴보면 사이즈에 관한 complain이 존재함을 알 수 있습니다. 추후 사이즈와 관련된 리뷰를 좀 더 깊게 살펴보겠습니다.