[SQL로 배우는 데이터 전처리 분석] 8. 상품 리뷰 데이터를 이용한 리포트 작성 (3) - Size Complain과 Clothing ID별 Size review
안녕하세요.
이번 포스팅은 review에 종종 나왔던 size에 대한 complain과 clothing id별 size review에 대해 분석해보겠습니다.
Size Complain
이전 포스팅에서 살펴본 내용에 따르면, Complain 내용의 다수가 Size에 관련한 문제였습니다.
먼저 전체 리뷰 내용 중 Size와 관련된 리뷰가 얼마나 되는지 확인하기 위해서 Review Text의 내용 중 size라는 단어가 언급된 Reivew가 몇 개인지 계산해보겠습니다.
SELECT `REVIEW TEXT`,
CASE WHEN `REVIEW TEXT` LIKE '%SIZE%' THEN 1 ELSE 0 END SIZE_YN
FROM MYDATA.DATASET2;
SIZE_YN은 리뷰의 내용 중 size가 포함되어 있으면 1, 그렇지 않으면 0인 값으로 출력됩니다.
전체의 리뷰 수에서 size가 포함된 리뷰의 수를 구해봅시다.
SELECT SUM(CASE WHEN `REVIEW TEXT` LIKE '%SIZE%' THEN 1 ELSE 0 END) N_SIZE,
COUNT(*) N_TOTAL
FROM MYDATA.DATASET2;
전체 리뷰 중 약 30%가량이 size와 관련된 리뷰였습니다. 다음으로 사이즈를 Large, Loose, Small, Tight로 상세히 나누어 살펴보겠습니다.
SELECT SUM(CASE WHEN `REVIEW TEXT` LIKE '%SIZE%' THEN 1 ELSE 0 END) N_SIZE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%LARGE%' THEN 1 ELSE 0 END) N_LARGE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%LOOSE%' THEN 1 ELSE 0 END) N_LOOSE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%SMALL%' THEN 1 ELSE 0 END) N_SMALL,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%TIGHT%' THEN 1 ELSE 0 END) N_TIGHT,
SUM(1) N_TOTAL
FROM MYDATA.DATASET2;
Large, Loose에 비해 Small, Tight와 관련된 리뷰가 더 많은 것으로 확인됩니다. 이것들을 카테고리별로 확인해보겠습니다.
SELECT `DEPARTMENT NAME`,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%SIZE%' THEN 1 ELSE 0 END) N_SIZE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%LARGE%' THEN 1 ELSE 0 END) N_LARGE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%LOOSE%' THEN 1 ELSE 0 END) N_LOOSE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%SMALL%' THEN 1 ELSE 0 END) N_SMALL,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%TIGHT%' THEN 1 ELSE 0 END) N_TIGHT,
SUM(1) N_TOTAL
FROM MYDATA.DATASET2
GROUP BY 1;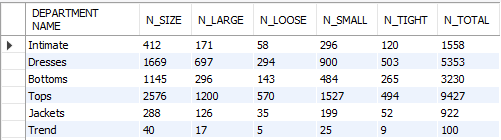
Dresses, Bottoms, Tops에서 사이즈와 관련된 리뷰가 많은 것으로 확인되었고, Dresses와 Bottoms는 Tops에 비해 small, tight와 관련된 리뷰가 많았습니다.
다음으로 이를 연령별로 나누어 보겠습니다.
SELECT FLOOR(AGE/10)*10 AGEBAND,
`DEPARTMENT NAME`,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%SIZE%' THEN 1 ELSE 0 END) N_SIZE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%LARGE%' THEN 1 ELSE 0 END) N_LARGE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%LOOSE%' THEN 1 ELSE 0 END) N_LOOSE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%SMALL%' THEN 1 ELSE 0 END) N_SMALL,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%TIGHT%' THEN 1 ELSE 0 END) N_TIGHT,
SUM(1) N_TOTAL
FROM MYDATA.DATASET2
GROUP BY 1, 2
ORDER BY 1, 2;
단순히 리뷰의 수를 계산하게 되면 Department에서 Size와 관련된 주된 Complain 내용이 무엇인지 파악하기가 어렵습니다.
그래서 절대 수가 아닌 비중을 구하겠습니다. 총 리뷰 수로 각 칼럼들을 나누면, 각 그룹에서 size 세부 그룹의 비중을 구할 수 있습니다.
SELECT FLOOR(AGE/10)*10 AGEBAND,
`DEPARTMENT NAME`,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%SIZE%' THEN 1 ELSE 0 END)/SUM(1) N_SIZE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%LARGE%' THEN 1 ELSE 0 END)/SUM(1) N_LARGE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%LOOSE%' THEN 1 ELSE 0 END)/SUM(1) N_LOOSE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%SMALL%' THEN 1 ELSE 0 END)/SUM(1) N_SMALL,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%TIGHT%' THEN 1 ELSE 0 END)/SUM(1) N_TIGHT,
SUM(1) N_TOTAL
FROM MYDATA.DATASET2
GROUP BY 1, 2
ORDER BY 1, 2;
총 리뷰 수를 SUM(1)과 같은 방법으로 계산했는데, 이는 COUNT(*)과 동일한 결과를 출력합니다.
결론적으로 연령대별, Department별 size Complain 원인을 파악할 수 있었습니다.
Clothing ID별 Size Review
연령, Department별로 사이즈와 관련된 리뷰를 살펴보았습니다. 이제 좀 더 세부적으로 어떤 상품이 Size와 관련된 리뷰 내용이 많은지 확인하겠습니다.
먼저 상품 ID별로 사이즈와 관련된 리뷰 수를 계산하고, 사이즈 타입별로 리뷰 수를 다시 집계해보겠습니다.
SELECT `CLOTHING ID`,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%SIZE%' THEN 1 ELSE 0 END) N_SIZE
FROM MYDATA.DATASET2
GROUP BY 1;
다음으로 사이즈 타입을 추가로 집계하겠습니다.
SELECT `CLOTHING ID`,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%SIZE%' THEN 1 ELSE 0 END) N_SIZE_T,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%SIZE%' THEN 1 ELSE 0 END)/SUM(1) N_SIZE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%LARGE%' THEN 1 ELSE 0 END)/SUM(1) N_LARGE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%LOOSE%' THEN 1 ELSE 0 END)/SUM(1) N_LOOSE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%SMALL%' THEN 1 ELSE 0 END)/SUM(1) N_SMALL,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%TIGHT%' THEN 1 ELSE 0 END)/SUM(1) N_TIGHT
FROM MYDATA.DATASET2
GROUP BY 1;
이제 어떤 옷이 사이즈와 관련된 Complain이 많고, 어떤 타입의 Complain이 많은 지 알게 되었습니다. 상품 개발팀이나 디자인팀에서 이 정보를 알고 있다면, 다음 상품을 개발할 때 큰 도움이 될 것입니다.
타 부서와 관련 내용을 공유하도록 새로운 테이블로 생성해보겠습니다.
CREATE TABLE MYDATA.SIZE_STAT_AS
SELECT `CLOTHING ID`,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%SIZE%' THEN 1 ELSE 0 END) N_SIZE_T,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%SIZE%' THEN 1 ELSE 0 END)/SUM(1) N_SIZE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%LARGE%' THEN 1 ELSE 0 END)/SUM(1) N_LARGE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%LOOSE%' THEN 1 ELSE 0 END)/SUM(1) N_LOOSE,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%SMALL%' THEN 1 ELSE 0 END)/SUM(1) N_SMALL,
SUM(CASE WHEN `REVIEW TEXT` LIKE '%TIGHT%' THEN 1 ELSE 0 END)/SUM(1) N_TIGHT
FROM MYDATA.DATASET2
GROUP BY 1;
마무리
상품 리뷰 데이터를 이용해서 텍스트 데이터를 다루어 보았습니다. 실제로 대부분의 상품명, 상품 카테고리, 회원 주소와 같은 정보는 텍스트로 되어있습니다.
내용을 잘 학습한다면, 텍스트 데이터도 SQL에서 어렵지 않게 다룰 수 있을 겁니다.
다음 포스팅부터는 식품 배송 데이터 분석에 대해서 학습하겠습니다.
감사합니다.
전체 코드는 아래 github를 참고해주시면 감사하겠습니다!
https://github.com/JunSeokCheon/Data-preprocessing-analysis-with-sql
GitHub - JunSeokCheon/Data-preprocessing-analysis-with-sql
Contribute to JunSeokCheon/Data-preprocessing-analysis-with-sql development by creating an account on GitHub.
github.com