[SQL로 배우는 데이터 전처리 분석] 9. 식품 배송 데이터 분석 (1) - 데이터 탐색 및 지표 추출
천 대리님, 식자재 배송 업체에서 데이터 분석해 달라는 요청이 들어왔습니다. 분석의 목적은 Business 현황과 재구매에 대한 insight입니다. 천 대리님이 자유롭게 분석해주시고, 인사이트 알려주세요.
이번 포스팅은 Instacart 데이터 셋 탐색과, 해당 Business의 전반적인 현황을 파악해보겠습니다.
데이터 탐색
처음 접하는 데이터가 있다면 항상 각 테이블이 무엇을 의미하는지, 어떤 칼럼이 있는지 확인하고 테이블 간의 관계를 파악해야 합니다.
aisles, departments, order_products_prior, orders, products 총 5개의 테이블이 존재합니다.
aisles, departments는 상품의 카테고리를 의미하고, order_products_prior는 각 주무 번호의 상세 구매 내역, orders는 주문 대표 정보, products 상품 정보를 의미합니다.
SELECT * FROM INSTACART.AISLES;
SELECT * FROM INSTACART.DEPARTMENTS;
SELECT * FROM INSTACART.ORDER_PRODUCTS__PRIOR;
SELECT * FROM INSTACART.ORDERS;
SELECT * FROM INSTACART.PRODUCTS;
지표 추출
재구매에 대한 현황을 찾기 전에 해당 Business의 전반적인 현황을 파악하겠습니다.
1) 전체 주문 건수
주문 건수와 구매자 수의 경우 ORDERS 테이블에서 중복으로 존재 가능하므로 distinct를 이용해 중복을 제외하고 카운트합니다.
데이터의 정합성을 보장하는 것은 매우 중요한 일이니 쿼리를 작성하기 전, 항상 데이터의 구조를 파악하고 수치를 구하는 것이 정론입니다.
SELECT COUNT(DISTINCT ORDER_ID) ORDER_COUNT
FROM INSTACART.ORDERS;
2) 구매자 수
SELECT COUNT(DISTINCT USER_ID) USER_COUNT
FROM INSTACART.ORDERS;
3) 상품별 주문 건수
상품별 주문 건수를 계산하기 위해서 상품명으로 데이터를 그룹핑하고 order_id를 카운트 집계하면 됩니다.
order_products__prior과 products 테이블을 product_id를 기준으로 join 해서 사용합니다.
SELECT *
FROM INSTACART.ORDER_PRODUCTS__PRIOR A
LEFT JOIN INSTACART.PRODUCTS B
ON A.PRODUCT_ID = B.PRODUCT_ID;
위와 같이 결합한 결과에서 product_name으로 데이터를 그룹핑하고, order_id를 카운트합니다.
여기서, order_id는 동일한 값이 중복으로 존재하므로 중복을 제거하고 집계합니다.
SELECT B.PRODUCT_NAME,
COUNT(DISTINCT A.ORDER_ID) ORDER_COUNT
FROM INSTACART.ORDER_PRODUCTS__PRIOR A
LEFT JOIN INSTACART.PRODUCTS B
ON A.PRODUCT_ID = B.PRODUCT_ID
GROUP BY 1;
4) 장바구니에 가장 먼저 넣는 상품 10개
ORDER_PRODUCTS__PRIOR 테이블에 ADD_TO_CART_ORDER라는 칼럼이 존재하고, 해당 칼럼은 몇 번째로 장바구니에 담겼는지를 의미합니다.
먼저 ORDER_PRODUCTS__PRIOR의 product_id 별로 가장 먼저 담긴 경우에 1을 출력하는 칼럼을 생성해보겠습니다.
SELECT PRODUCT_ID,
CASE WHEN ADD_TO_CART_ORDER = 1 THEN 1 ELSE 0 END CART_1ST
FROM INSTACART.ORDER_PRODUCTS__PRIOR;
상품 번호로 데이터를 그룹핑하고 CART_1ST 칼럼을 합하면, 상품별 장바구니에 가장 먼저 담긴 건수를 계산할 수 있습니다.
SELECT PRODUCT_ID,
SUM(CASE WHEN ADD_TO_CART_ORDER = 1 THEN 1 ELSE 0 END ) CART_1ST
FROM INSTACART.ORDER_PRODUCTS__PRIOR
GROUP BY 1;
이제 CART_1ST로 데이터의 순서를 매깁니다.
SELECT *,
ROW_NUMBER() OVER(ORDER BY CART_1ST DESC) RNK
FROM
(SELECT PRODUCT_ID,
SUM(CASE WHEN ADD_TO_CART_ORDER = 1 THEN 1 ELSE 0 END ) CART_1ST
FROM INSTACART.ORDER_PRODUCTS__PRIOR
GROUP BY 1) A;
우리는 1-10위의 상품 번호만 궁금하므로 WHERE 절에 조건을 추가하여 1-10위 데이터만 출력합니다.
이때 RNK는 SELECT에서 새롭게 생성한 칼럼이므로 WHERE 절에서 바로 사용할 수 없기 때문에 SUBQUERY로 사용해 조건을 생성해야 합니다.
SELECT *
FROM
(SELECT *,
ROW_NUMBER() OVER(ORDER BY CART_1ST DESC) RNK
FROM
(SELECT PRODUCT_ID,
SUM(CASE WHEN ADD_TO_CART_ORDER = 1 THEN 1 ELSE 0 END ) CART_1ST
FROM INSTACART.ORDER_PRODUCTS__PRIOR
GROUP BY 1) A) BASE
WHERE RNK <= 10;
5) 시간별 주문 건수
ORDERS의 ORDER_HOUR_OF_DAY로 그룹핑한 뒤, ORDER_ID의 중복 처리 후 ORDER_ID를 카운트합니다.
SELECT ORDER_HOUR_OF_DAY,
COUNT(DISTINCT ORDER_ID) ORDER_COUNT
FROM INSTACART.ORDERS
GROUP BY 1
ORDER BY 1;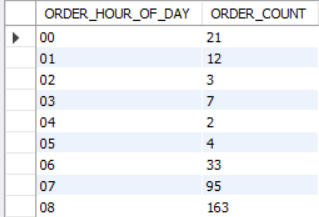
6) 첫 구매 후 다음 구매까지 걸린 평균 일수
ORDERS 테이블에서 DAYS_SINCE_PRIOR_ORDER는 이전 주문이 이루어진 지 며칠 뒤에 구매가 이루어졌는지 나타내는 값입니다.
즉, 주문 번호의 ORDER_NUMBER가 2인(해당 유저의 2번째 주문 건) DAYS_SINCE_PRIOR_ORDER가 첫 구매 후 다음 구매까지 걸린 기간이 됩니다. 이 값을 평균하면 평균 일수를 구할 수 있습니다.
SELECT AVG(DAYS_SINCE_PRIOR_ORDER) AVG_RECENCY
FROM INSTACART.ORDERS
WHERE ORDER_NUMBER = 2;
7) 주문 건당 평균 구매 상품 수(UPT, Unit Per Transaction)
PRODUCT_ID를 카운트해 상품 개수를 계산하고, 이를 주문 건수로 나누어 주문 1건에 평균적으로 몇 개의 상품을 구매하는 파악 합니다.
SELECT COUNT(PRODUCT_ID)/COUNT(DISTINCT ORDER_ID) UPT
FROM INSTACART.ORDER_PRODUCTS__PRIOR;
8)인당 평균 주문 건수
전체 주문 건수를 구매자 수로 나누어 인당 평균 주문 건수를 구할 수 있습니다.
SELECT COUNT(DISTINCT ORDER_ID) / COUNT(DISTINCT USER_ID) AVG_COUNT
FROM INSTACART.ORDERS;
9) 재구매율이 가장 높은 상품 10개
재구매율이 가장 높은 상품을 구하기 위해서 먼저 상품별로 재구매율을 계산한 뒤, 재구매율을 기준으로 랭크를 계산합니다. 이후, 원하는 랭크 값으로 조건을 생성해서 상품을 추출합니다.
a) 상품별 재구매율 계산
상품 번호로 데이터를 그룹핑한 후, ORDER_PRODUCTS__PRIOR 테이블의 REORDERED 칼럼을 활용해 재구매 수를 전체 구매 수로 나누어 재구매율을 계산합니다.
SELECT PRODUCT_ID,
SUM(CASE WHEN REORDERED = 1 THEN 1 ELSE 0 END)/COUNT(*) REORDER_RATIO
FROM INSTACART.ORDER_PRODUCTS__PRIOR
GROUP BY 1;
b) 재구매율로 순위열 생성하기
앞에서 생성한 상품별 재구매율로 순위를 구합니다. 앞의 결과를 SUBQUERY로 생성하고, SELECT 문에서 순위 문(ROW_NUMBER, RANK, DENSE_RANK)을 사용해서 순위 열을 생성합니다.
SELECT *,
ROW_NUMBER() OVER(ORDER BY REORDER_RATIO DESC) RNK
FROM
(SELECT PRODUCT_ID,
SUM(CASE WHEN REORDERED = 1 THEN 1 ELSE 0 END)/COUNT(*) REORDER_RATIO
FROM INSTACART.ORDER_PRODUCTS__PRIOR
GROUP BY 1) A;
c) Top 10 상품 추출
상품별로 재구매율을 계산하고, 재구매율 순위 열을 생성했습니다. 생성한 순위 열에서 1-10 데이터를 추출하면 됩니다.
SELECT *
FROM
(SELECT *,
ROW_NUMBER() OVER(ORDER BY REORDER_RATIO DESC) RNK
FROM
(SELECT PRODUCT_ID,
SUM(CASE WHEN REORDERED = 1 THEN 1 ELSE 0 END)/COUNT(*) REORDER_RATIO
FROM INSTACART.ORDER_PRODUCTS__PRIOR
GROUP BY 1) A) BASE
WHERE RNK <= 10;
10) Department별 재구매율이 가장 높은 상품 10개
Department별로 재구매율이 높은 상품을 추출하려면, Department/상품별 그룹핑하여 재구매율을 계산해야 합니다.
앞 9번 예제에서 추가된 내용은 ORDER_PRODUCTS__PRIOR에 PRODUCTS 테이블을 조인해 DEPARTMENT를 가져와야 한다는 점과 DEPARTMENT로 PARTITION을 생성해 순위를 매겨야 한다는 것을 유의하고 수행해보겠습니다.
SELECT *
FROM
(SELECT *,
ROW_NUMBER() OVER(ORDER BY REORDER_RATIO DESC) RNK
FROM
(SELECT C.DEPARTMENT,
A.PRODUCT_ID,
SUM(CASE WHEN REORDERED = 1 THEN 1 ELSE 0 END)/COUNT(*) REORDER_RATIO
FROM INSTACART.ORDER_PRODUCTS__PRIOR A
LEFT JOIN INSTACART.PRODUCTS B
ON A.PRODUCT_ID = B.PRODUCT_ID
LEFT JOIN INSTACART.DEPARTMENTS C
ON B.DEPARTMENT_ID = C.DEPARTMENT_ID
GROUP BY 1, 2) A) A
WHERE RNK <= 10;