[AWS] AWS 기반 데이터 파이프라인 구축하기 [1] - Analytics on AWS(Kinesis Data Firehose, S3)
전제 조건
- AWS 계정에서 AdminstratorAccess에 대한 액세스 권한이 있어야합니다.
- 이 실습은 us-east-1 리전에서 실행되어야 합니다.
- 최신 브라우저에서 이 실습을 실행하세요.
실습 과정
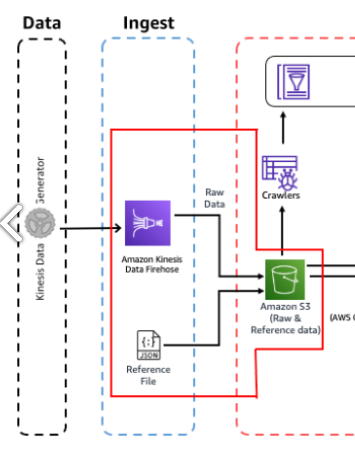
- Kinesis 데이터 생성기 유틸리티를 사용하여 거의 실시간으로 Dummy 데이터를 생성
- Kinesis delivery stream을 사용하여 Amazon S3로 데이터를 전송
- 또한 일부 참조 데이터를 S3 버킷에 직접 복사

| 사용되는 서비스 | 서비스 설명 | 비고 |
| Amazon Kinesis Data Firehose | 스트리밍 데이터를 미리 정의된 목적지(데이터 레이크)에 데이터를 안전하게 전달하는 추출, 변환, 로드 서비스 | 스트리밍 데이터? 고객, 애플리케이션, 시스템에서 실시간으로 생성되는 데이터 데이터 레이크? 빅데이터를 위한 데이터 스토리지 리포지토리 현재 정의된 용도가 없는 원시 데이터를 저장 |
| Amazon S3 | 클라우드 객체 스토리지 서비스 | 객체? 데이터와 메타데이터를 구성하고 있는 저장 단위 버킷? 이런 객체를 저장하고 관리하는 역할 |
S3 버킷 생성
데이터를 적재하기 위한 저장소를 만들어 주기 위해 S3 버킷을 생성한다.

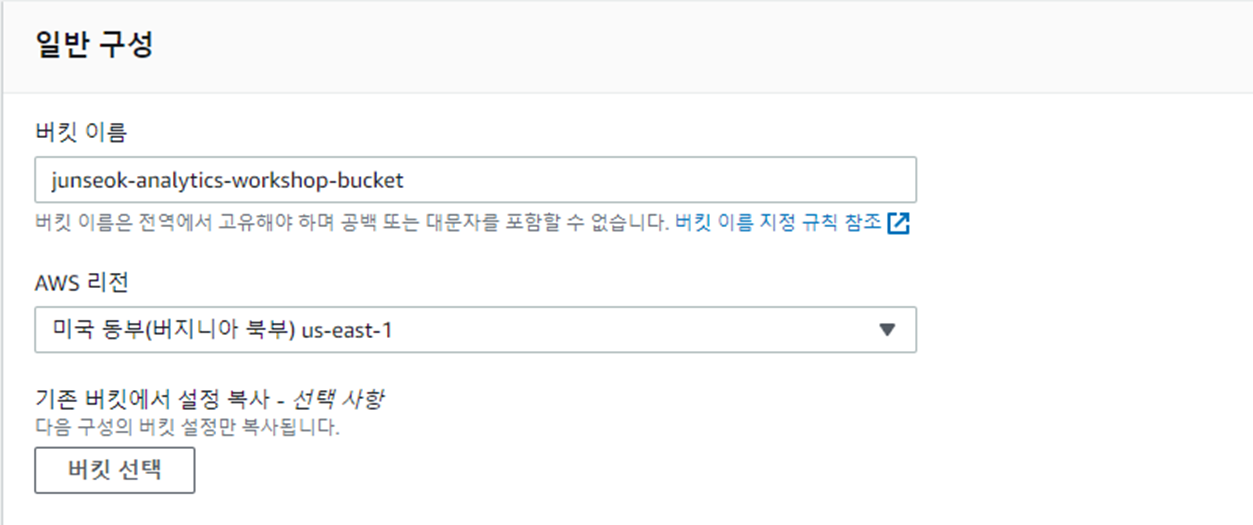


결과
버킷 : junseok-analytics-workshop-bucket
내부 폴더 1 : data
내부 폴더 2 : reference_data
생성 완료
데이터 적재
reference_data 폴더에 아래 링크의 json 파일 다운로드 후 업로드



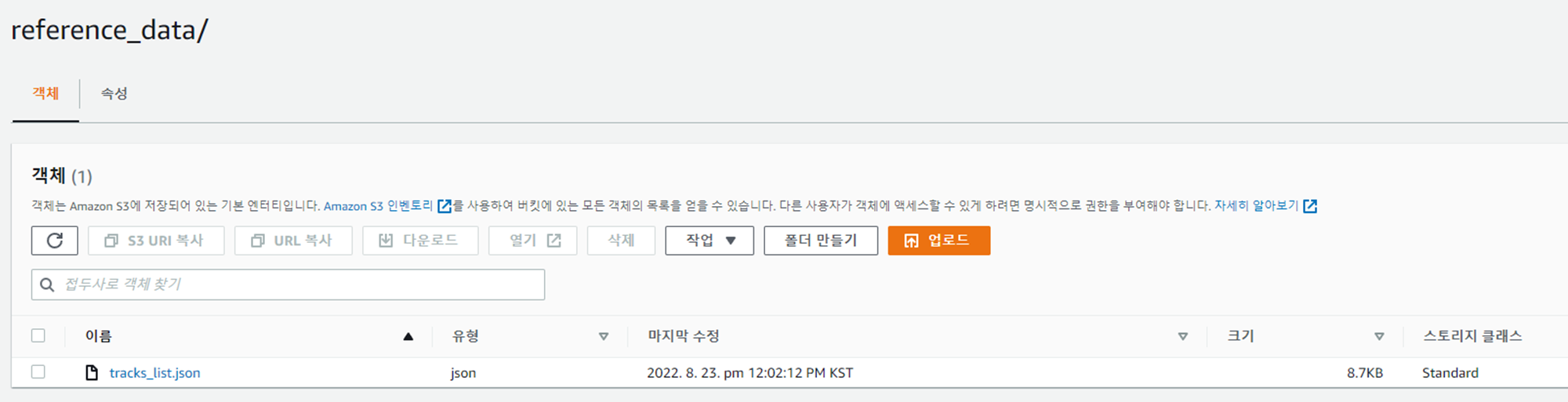
결과
S3 -> junseok-analytics-workshop-bucket -> data -> reference_data -----------> tracks_list.json 데이터 적재 완료
Kinesis Firehose 생성
Kinesis 콘솔로 이동하여 Kinesis Firehose delevery stream을 생성하여 S3에 데이터를 수집하고 저장한다.







- Source : Driect PUT (수동으로 직접 코드를 올리고, 완전한 실시간은 아니다) - Kinesis data stream과 비교 링크 https://stackoverflow.com/questions/62587569/kinesis-data-firehose-source-direct-put-vs-kinesis-data-stream
- Destination : Amazon S3
- Delivery stream name : analytics-workshop-stream
- S3 bucket : s3://junseok-analytics-workshop-bucket
- Prefix : data/raw - raw 이후의 슬래쉬(/)는 중요하다. 이 부분이 없으면 Firehose가 데이터를 원하지 않는 위치에 복사 할 것이다.
- S3 Buffer size : 1 (MB)
- S3 Buffer interval : 60 (sec)
- S3 compression : Disabled
- S3 encryption : Disabled
- Error logging : Enabled
- IAM role : 기본값인 Create or update IAM role KinesisFirehoseServiceRole-analytics-wor-us-east-xxxx 유지
결과
raw 데이터를 저장할 곳을 만들고, firehose를 사용하여 데이터를 ETL 할 준비를 마쳤다.
더미 데이터 생성
더미 데이터를 생성하고 Kinesis Firehose로 수집하도록 Kinesis Data Generator를 구성한다.
Kinesis Data Generator용 Amazon Cognito 구성 - 이 단계에서는 Cognito를 구성 할 Cloudformation 스택을 실행한다.
이 CloudFormation 스크립트는 N.Virginia 리전에서 실행된다.
- 템플릿 지정
- 스택 세부 정보 지정
- 스택 옵션 구성
- 검토
위 4단계로 구성되어 있으며, 스택 세부 정보 지정에서 Username, Password를 입력하고 검토 단계까지 진행하면 된다.


amazon kinesis data generator 홈페이지로 연결되고, 이전에 지정한 아이디와 비밀번호로 로그인 한다.

{
"uuid": "{{random.uuid}}",
"device_ts": "{{date.utc("YYYY-MM-DD HH:mm:ss.SSS")}}",
"device_id": {{random.number(50)}},
"device_temp": {{random.weightedArrayElement(
{"weights":[0.30, 0.30, 0.20, 0.20],"data":[32, 34, 28, 40]}
)}},
"track_id": {{random.number(30)}},
"activity_type": {{random.weightedArrayElement(
{
"weights": [0.1, 0.2, 0.2, 0.3, 0.2],
"data": ["\"Running\"", "\"Working\"", "\"Walking\"", "\"Traveling\"", "\"Sitting\""]
}
)}}
}약 2만개 데이터를 생성한다.
도구에서 ~ 20,000 개의 메시지를 보내면 - Stop sending data to Kinesis 클릭하자.
데이터가 S3에 도착했는지 확인
버킷-data-raw 폴더를 연 뒤 데이터가 도착했는지 확인한다.
firehose가 yyyy/mm/dd/hh 파티셔닝을 사용하여 데이터를 S3를 덤프 했다는 것을 알 수 있다.

마무리
S3 버킷을 생성한 뒤 reference_data 폴더에 track_list 데이터, data 폴더에 더미 데이터를 적재했다.