[AWS] AWS 기반 데이터 파이프라인 구축하기 [4] - Analytics on AWS(AWS Glue Studio)
실습 과정
- 이전 포스팅에서 수행한 SageMaker을 활용하여 직접 코드로 변환한 작업을 Glue Studio의 새로운 그래픽 인터페이스를 사용하여 코드리스로 데이터 변환
- 데이터 변환 워크플로우를 시각적으로 구성하고 AWS Glue의 Apache Spark 기반 서버리스 ETL 엔진에서 실행

| 사용되는 서비스 | 서비스 설명 | 비고 |
| AWS Glue Studio | AWS Glue Studio는 AWS Glue에서 추출, 변환 및 로드(ETL) 작업을 쉽게 생성, 실행 및 모니터링 할 수 있는 새로운 그래픽 인터페이스(서버리스) |
AWS Glue Studio를 이용한 데이터 변환
Glue Studio 콘솔 이동 후 좌측 메뉴 jobs 클릭한다.

- jobs 클릭 후 Visual with a blank canvas 생성

- Source - S3 선택

- 오른쪽 Data source properties - S3 탭 설정
- S3 source type : Data Catalog table
- Database : analyticsworkshopdb
- Table : raw

위와 같은 작업을 reference data도 동일하게 생성한다.

- 임의의 노드를 선택 후 Transform - join

- join을 하기 위해서 다른 노드가 필요하기 때문에 Node properties 탭에서 다른 노드 추가
사진을 보면 주의가 나타나는데, 두 노드 사이 간의 join conditions이 정해지지 않아서 나타난 것이다.
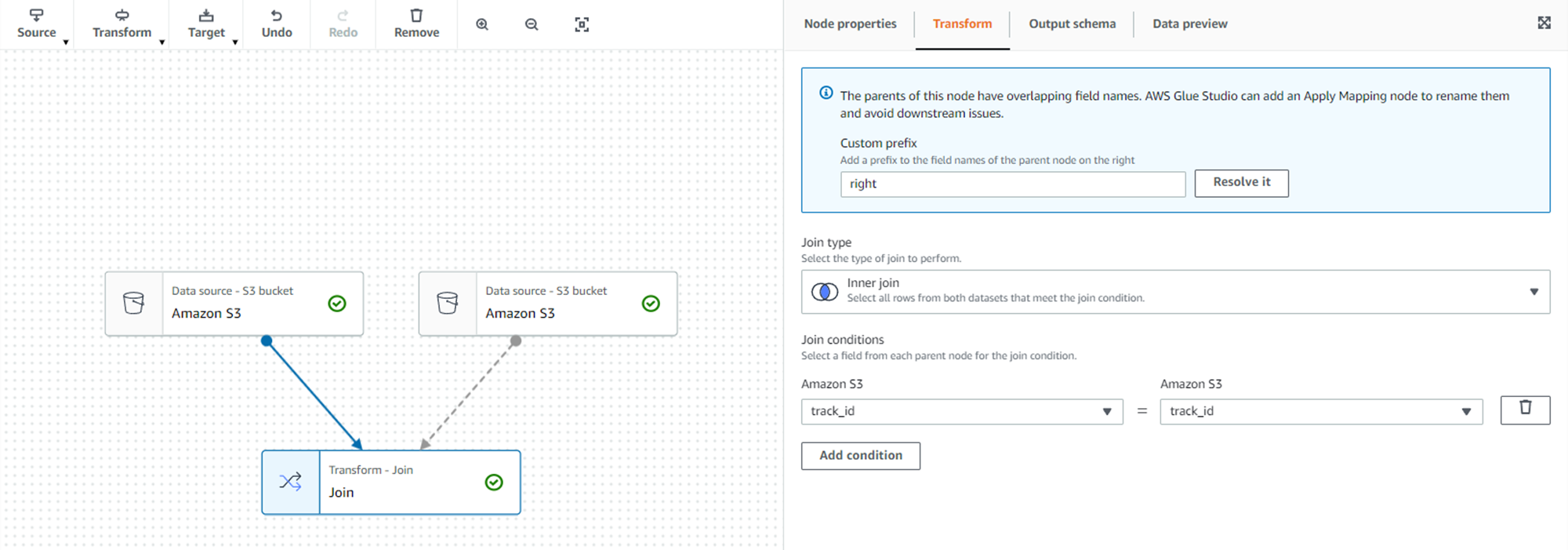
- Transform - Join conditions - Add condition의 공통된 칼럼인 track_id 칼럼을 조인 열로 선택


- join 노드 선택 후 Transform - ApplyMapping에서 칼럼들의 mapping 정보 확인

사용하지 않은 칼럼 삭제하고 새로운 데이터 유형을 매핑한다.
- drop columns : partition_0, partition_1, partition_2, partition_3
- change data type : track_id STRING
(* 주의 .track_id 칼럼도 삭제해야 하는데 이상하게도 Transform에 나타나지 않아서 Script 탭에서 직접 pyspark 코드를 수정함)


- ApplyMapping 노드 선택 후 Target - S3 선택
- 오른쪽 Data source properties - S3 탭 수정
- Format : Parquet
- Compression Type: Snappy
- S3 Target Location: s3://yourname-analytics-workshop-bucket/data/processed-data2/
- Data Catalog update options : Choose Create a table in the Data Catalog and on subsequent runs, update the schema and add new partitions
- Database: analyticsworkshopdb
- Table name: processed-data2


Job details 클릭하고 다음 옵션으로 구성한다.
- Name: AnalyticsOnAWS-GlueStudio
- IAM Role: AnalyticsWorkshopGlueRole
- Number of workers: 2
- Job bookmark: Disable
- Number of retries: 1
- Job timeout (minutes): 10
- 나머지 기본 값 후 Save 클릭

Save를 누르면 "Successfully created job"이 표시가 되고, 화면 오른쪽 상단의 Run을 클릭하여 ETL 작업을 시작한다.

잠시 기다리면 Runs 탭에서 ETL 작업 실행 상태가 "Succeeded"로 표시된다.

Glue Studio에서 생성 한 Pyspark 코드를 확인할 수 있으며, 필요한 경우 다른 용도로 이 코드를 사용할 수 있다.

Glue DataCatalog로 이동하면 analyticsworkshopdb 데이터베이스 아래에 생성된 processed-data2 테이블을 확인할 수 있다.
마무리
AWS Glue Studio로 추가 ETL 실습을 수행했다.
AWS Glue Studio를 사용하면 데이터 변환 워크 플로우를 시각적으로 구성하고 AWS Glue의 Apache Spark 기반 서버리스 ETL 엔진에서 원활하게 실행할 수 있는 장점을 가지고 있다.
다음 포스팅은 Amazon EMR을 사용하여 pyspark 작업을 통해 데이터를 조작하여 S3에 저장할 것이다.