이번 포스팅은 연도별 재구매율과 best seller 제품 추출과 churn rate를 계산하여 비즈니스를 더 이해해보도록 하겠습니다.
ERD

재구매율
연도별로 재구매율을 계산합니다. 재구매율은 특정 기간 1 구매자 중 특정 기간 2에 연달아 구매한 구매자의 비중을 의미합니다.
ORDERS 테이블을 결합하는데 CUSTOMERNUMBER와 ORDERDATE의 데이터를 결합하게 됩니다.
이때 ORDER(A)의 SUBSTR(A ..)와 B의 SUBSTR(B ..) - 1을 결합하게 되어 A를 기준으로 1년 단위의 구매율을 비교합니다.
예를 들어, 2003년도 거래 건에는 2004년도 거래가 매칭 되지만 2004년도 거래 건에는 2005년 거래가 없어서 어떤 값도 매칭 되지 않습니다.
A의 주문 연도로 그룹핑한 후 A와 B의 CUSTOMERNUMBER를 기준으로 COUNT 하면 구매자 수를 알 수 있고, 두 값을 나누면 최종적으로 각 연도의 Retention rate를 구할 수 있습니다.
SELECT SUBSTR(A.ORDERDATE, 1, 4) YY,
COUNT(DISTINCT A.CUSTOMERNUMBER) CLI_1,
COUNT(DISTINCT B.CUSTOMERNUMBER) CLI_2,
COUNT(DISTINCT B.CUSTOMERNUMBER)/COUNT(DISTINCT A.CUSTOMERNUMBER) RETENTION_RATE
FROM CLASSICMODELS.ORDERS A
LEFT JOIN CLASSICMODELS.ORDERS B
ON A.CUSTOMERNUMBER = B.CUSTOMERNUMBER AND SUBSTR(A.ORDERDATE, 1, 4) = SUBSTR(B.ORDERDATE, 1, 4) - 1
GROUP BY 1;
국가별 재구매율
쿼리를 작성하기 전에 데이터를 어떻게 구조화해야 할지 생각합니다.
A 국가 거주 구매자 중 다음 연도에도 구매를 한 구매자의 비중으로 구할 수 있습니다.
앞에서 작성한 쿼리에 고객의 거주 국가 정보를 결합한 후 거주 국가로 그룹핑해 재구매율을 구하면 됩니다.
SELECT C.COUNTRY,
SUBSTR(A.ORDERDATE, 1, 4) YY,
COUNT(DISTINCT A.CUSTOMERNUMBER) CLI_1,
COUNT(DISTINCT B.CUSTOMERNUMBER) CLI_2,
COUNT(DISTINCT B.CUSTOMERNUMBER)/COUNT(DISTINCT A.CUSTOMERNUMBER) RETENTION_RATE
FROM CLASSICMODELS.ORDERS A
LEFT JOIN CLASSICMODELS.ORDERS B
ON A.CUSTOMERNUMBER = B.CUSTOMERNUMBER AND SUBSTR(A.ORDERDATE, 1, 4) = SUBSTR(B.ORDERDATE, 1, 4) - 1
LEFT JOIN CLASSICMODELS.CUSTOMERS C
ON A.CUSTOMERNUMBER = C.CUSTOMERNUMBER
GROUP BY 1, 2;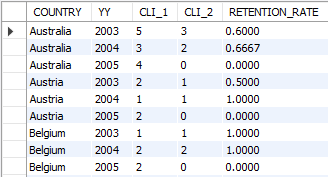
Best Seller
천 대리님, 전달해 주신 내용을 보니 미국의 고객 Retention Rate가 가장 높은 것으로 확인됩니다. 미국으로 한정해 데이터를 좀 더 뽑아 보려고 합니다. 미국의 연도별 Top 5 차량 모델 추출을 부탁드립니다.

다른 나라에 비해 클라이언트 시장이 가장 큰 것으로 파악되었습니다. 큰 시장에 집중하기 위해 좀 더 디테일한 내용을 추출하고자 합니다.
미국의 TOP 5 제품명을 추출하기 위해서 필요한 테이블은 총 4개입니다.
결합해야 할 테이블이 많은 뿐 로직이 복잡하진 않아 ERD를 보고 충분히 쉽게 결합할 수 있습니다.
쿼리가 너무 길어진다면 아래와 같이 테이블로 데이터를 생성 후, 한번 더 쿼리를 작성해 추출하는 것이 좋습니다.
CREATE TABLE CLASSICMODELS.PRODUCT_SALES AS
SELECT D.PRODUCTNAME,
SUM(C.QUANTITYORDERED * C.PRICEEACH) SALES
FROM CLASSICMODELS.ORDERS A
LEFT JOIN CLASSICMODELS.CUSTOMERS B
ON A.CUSTOMERNUMBER = B.CUSTOMERNUMBER
LEFT JOIN CLASSICMODELS.ORDERDETAILS C
ON A.ORDERNUMBER = C.ORDERNUMBER
LEFT JOIN CLASSICMODELS.PRODUCTS D
ON C.PRODUCTCODE = D.PRODUCTCODE
WHERE B.COUNTRY = 'USA'
GROUP BY 1;
SELECT *
FROM
(SELECT *,
ROW_NUMBER() OVER(ORDER BY SALES DESC) RNK
FROM CLASSICMODELS.PRODUCT_SALES) A
WHERE RNK <= 5
ORDER BY RNK;
churn rate(%)
churn rate란 고객 중 얼마나 많은 고객이 비활동 고객으로 전환되었는지를 의미하는 지표입니다. 고객 1명을 획득하는 비용을 Acquisition Cost라고 부릅니다.
기업들은 신규 고객을 유치하는데 생각보다 큰 비용을 사용하기 때문에 한 번 획득한 고객을 Active로 유지하는 것은 굉장히 중요한 일입니다.
chrun rate를 구하기 전에 chrun에 대한 정의가 필요한데, 일반적으로 churn은 다음과 같이 정의합니다.
churn : max(구매일, 접속일) 이후 일정 기간(ex. 3개월) 구매, 접속하지 않는 상태
1) Churn Rate(%) 구하기
classicmodels를 이용한 churn rate를 구해보겠습니다. 먼저 orders 테이블에서 마지막 구매일을 확인합니다.
SELECT MAX(ORDERDATE) MX_ORDER
FROM CLASSICMODELS.ORDERS;
2005-06-01일을 기준으로 각 고객의 마지막 구매일이 며칠 소요되었는지를 구해보겠습니다.
먼저 각 고객의 마지막 구매일을 구합니다.
SELECT CUSTOMERNUMBER,
MAX(ORDERDATE) MX_ORDER
FROM CLASSICMODELS.ORDERS
GROUP BY 1;
다음으로 2005-06-01 기준으로 며칠이 소요되었는지 계산합니다. 계산에는 DATEDIFF() 함수를 사용합니다.
SELECT CUSTOMERNUMBER,
MX_ORDER, '2005-06-01',
DATEDIFF('2005-06-01', MX_ORDER) DIFF
FROM
(SELECT CUSTOMERNUMBER,
MAX(ORDERDATE) MX_ORDER
FROM CLASSICMODELS.ORDERS
GROUP BY 1) BASE;
DIFF는 MX_ORDER와 END_POINT의 차이를 나타냅니다. 우리는 DIFF가 90일 이상인 경우를 Churn이라고 가정하겠습니다.
SELECT *,
CASE WHEN DIFF >= 90 THEN 'CHURN' ELSE 'NON-CHURN' END CHURN_TYPE
FROM
(SELECT CUSTOMERNUMBER,
MX_ORDER, "2005-06-01",
DATEDIFF("2005-06-01", MX_ORDER) DIFF
FROM
(SELECT CUSTOMERNUMBER,
MAX(ORDERDATE) MX_ORDER
FROM CLASSICMODELS.ORDERS
GROUP BY 1) BASE) BASE;
DIFF가 90 이상이면 CHURN, 그렇지 않은 경우 NON-CHURN으로 구분했습니다. 이제 CHRUN RATE(%)를 구해봅니다.
SELECT CASE WHEN DIFF >= 90 THEN "CHURN" ELSE "NON-CHRUN" END CHURN_TYPE,
COUNT(DISTINCT CUSTOMERNUMBER) N_CUS
FROM
(SELECT CUSTOMERNUMBER,
MX_ORDER, "2005-06-01" END_POINT,
DATEDIFF("2005-06-01", MX_ORDER) DIFF
FROM
(SELECT CUSTOMERNUMBER,
MAX(ORDERDATE) MX_ORDER
FROM CLASSICMODELS.ORDERS
GROUP BY 1) BASE) BASE
GROUP BY 1;
CHRUN RATE는 69/(69+29) = 0.70으로, 약 70%로 높은 수치로 나타납니다.
2) Churn 고객이 가장 많이 구매한 Productline
앞에서 Churn rate와 Churn 고객을 구해보았습니다.
이제 Churn 고객의 특성을 파악해보려고 하는데, 먼저 churn 고객은 어떤 카테고리의 상품을 많이 구매했는지 파악해보겠습니다.
고객별 Churn Table을 생성하겠습니다.
CREATE TABLE CLASSICMODELS.CHRUN_LIST AS
SELECT CASE WHEN DIFF >= 90 THEN "CHURN" ELSE "NON-CHURN" END CHURN_TYPE,
CUSTOMERNUMBER
FROM
(SELECT CUSTOMERNUMBER,
MX_ORDER, "2005-06-01" END_POINT,
DATEDIFF("2005-06-01", MX_ORDER) DIFF
FROM
(SELECT CUSTOMERNUMBER,
MAX(ORDERDATE) MX_ORDER
FROM CLASSICMODELS.ORDERS
GROUP BY 1) BASE) BASE;
다음으로 ORDERDETAILS - ORDERS - PRODUCTS를 결합해 PRODUCTLINE별 구매주 수를 구해보도록 하겠습니다.
SELECT C.PRODUCTLINE,
COUNT(DISTINCT B.CUSTOMERNUMBER) CLI
FROM CLASSICMODELS.ORDERDETAILS A
LEFT JOIN CLASSICMODELS.ORDERS B
ON A.ORDERNUMBER = B.ORDERNUMBER
LEFT JOIN CLASSICMODELS.PRODUCTS C
ON A.PRODUCTCODE = C.PRODUCTCODE
GROUP BY 1;
우리가 구하고 싶은 것은 CHURN TYPE, PRODUCT LINE별 구매자 수입니다.
앞에서 생성한 CLASSICMODELS.CHURN_LIST를 결합해 CHURN TYPE으로 데이터를 한번 더 나눠줘야 합니다.
SELECT D.CHURN_TYPE,
C.PRODUCTLINE,
COUNT(DISTINCT B.CUSTOMERNUMBER) CLI
FROM CLASSICMODELS.ORDERDETAILS A
LEFT JOIN CLASSICMODELS.ORDERS B
ON A.ORDERNUMBER = B.ORDERNUMBER
LEFT JOIN CLASSICMODELS.PRODUCTS C
ON A.PRODUCTCODE = C.PRODUCTCODE
LEFT JOIN CLASSICMODELS.CHURN_LIST D
ON B.CUSTOMERNUMBER = D.CUSTOMERNUMBER
GROUP BY 1, 2
ORDER BY 1, 3 DESC;
CHURN TYPE과 PRODUCTLINE과 큰 연관이 없는 것처럼 보입니다.
마무리
이번 자동차 매출 데이터를 이용한 리포트 작성에서 CLASSICMODELS라는 데이터베이스를 이용해 각종 지표를 추출해 보았습니다. 해당 데이터베이스는 여러 개의 테이블로 구성되어 있어서 JOIN을 익히기 좋은 예제였습니다.
다음 포스팅부터는 상품 리뷰 데이터를 이용한 리포트 작성을 해보겠습니다.
감사합니다.
전체 코드는 아래 github를 참고해주시면 감사하겠습니다!
https://github.com/JunSeokCheon/Data-preprocessing-analysis-with-sql
GitHub - JunSeokCheon/Data-preprocessing-analysis-with-sql
Contribute to JunSeokCheon/Data-preprocessing-analysis-with-sql development by creating an account on GitHub.
github.com




댓글