728x90
실습 과정
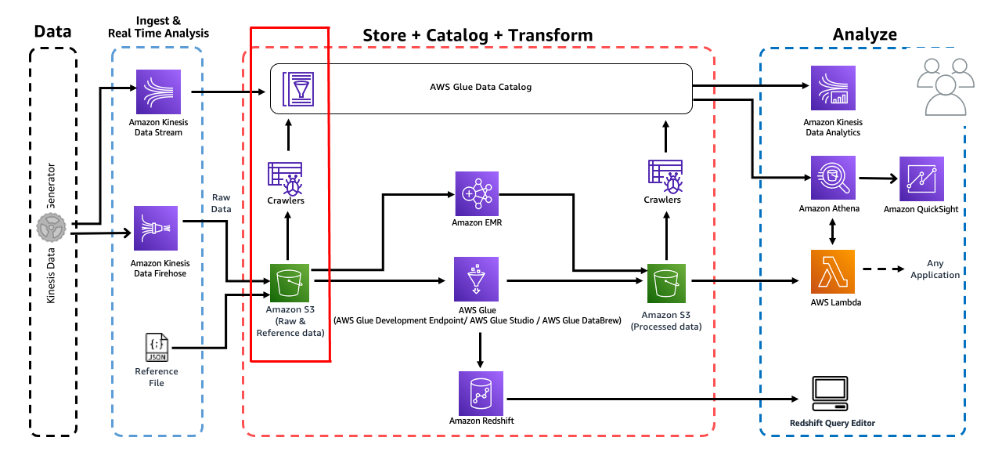
- S3에 저장된 데이터를 Glue Crawlers의 도움으로 AWS Glue Data Catalog에 데이터 세트를 등록
- 카탈로그 엔터티가 생성되면 Amazon Athena에서 데이터의 raw 포맷의 데이터에 대해 쿼리를 시작
| 사용되는 서비스 | 서비스 설명 | 비고 |
| Amazon Glue | 작업을 정의하여 데이터 원본에서 데이터 대상으로 데이터를 추출, 변환, 로드하는 데 필요한 작업을 수행한다. 원본 데이터에서 크롤러를 정의하여 메타데이터 테이블 정의로 AWS Glue Data Catalog를 채운다. |
데이터 카탈로그란? 영구적 메타데이터 스토어 s3의 데이터를 테이블처럼 만드는 것을 카탈로그로 만든다고 한다. 데이터를 Glue Data Catalog에 등록시켜 놓으면 aws의 다른 분석 서비스에서 활용 할 수 있다. |
| Amazon Athena | 표준 SQL을 사용해 S3에 저장된 데이터를 간편하게 분석할 수 있는 대화식 쿼리 서비스 |
IAM Role 생성
AWS Glue를 사용하기 전 IAM 콘솔로 이동하여 새 AWS Glue service role을 생성해야 한다.
이를 통해 AWS Glue는 S3에 저장된 데이터에 액세스하고 Glue 데이터 카탈로그에서 필요한 엔터티를 생성할 수 있다.





- 사용할 서비스 : Glue
- 권한 : AmazonS3 FullAccess, AWSGlueServiceRole 추가
- Role name : AnalyticsworkshopGlueRole
- 권한 확인 후 Create role 클릭
AWS Glue Crawlers 생성
AWS Glue 콘솔로 이동 후 왼쪽 패널에 크롤러 선택하고 크롤러 생성







- 크롤러 이름 : AnalyticsworkshopCrawler
- Crawler source type : Data stores
- Data store: S3
- Include path: s3://yourname-analytics-workshop-bucket/data/
- Add another data store: No
- IAM Role : AnalyticsworkshopGlueRole (미리 정의한 IAM Role 선택)
- Schedule : Run on demand
- Output : analyticsworkshopdb 이름의 데이터베이스 추가
- 정보 확인 후 크롤러 생성
- 크롤러 생성 후 실행하면 S3에 있는 raw, reference_data 2개의 테이블 추가된 것을 확인
카탈로그에서 새로 생성된 테이블 확인
Glue 카탈로그로 이동하여 크롤링된 데이터 탐색



- analyticsworkshopdb 클릭 후 analyticsworkshopdb 내 테이블 클릭
- 각 테이블을 확인하고 옵션/스키마 탐색
Amazon Athena를 사용하여 수집된 데이터 쿼리
Amazon Athena를 사용하여 새로 수집된 데이터를 쿼리
"첫 번째 쿼리를 실행하기 전에, Amazon S3에서 쿼리 결과 위치를 설정해야 합니다"라는 경고창이 보인다면
보기 설정 -> 관리 -> s3://yourname-analytics-workshop-bucket/query_results/ 입력

SELECT * FROM "analyticsworkshopdb"."raw" limit 10;
- 왼쪽 패널에서 (Database) 드롭 다운 , analyticsworkshopdb 선택 후 raw 테이블 선택
- 표준 SQL 쿼리 언어를 사용해 테이블 결과 확인
SELECT activity_type,
count(activity_type)
FROM raw
GROUP BY activity_type
ORDER BY activity_type
- 원하는 데이터를 쿼리를 작성하여 결과를 확인 가능
마무리
S3에 저장된 데이터를 crawler를 활용하여 data catalog로 저장하여 athena에서 쿼리로 원하는 데이터를 확인 가능했다.
다음 포스팅은 AWS Glue ETL을 사용하여 데이터를 변환하는 작업을 진행할 것이다.




댓글