항공사 고객 만족도 예측 대회 포스팅 시작하겠습니다.
프로젝트 구성은 Simple EDA -> Deep EDA -> 모델 설계 -> 모델 학습입니다.
이번 포스팅은 보충 EDA, 이상치 확인/처리, 데이터 전처리, 모델 학습, 모델 앙상블, 모델 튜닝, 제출로 구성되어 있습니다.
시작은 아래 포스팅 이후부터 다루겠습니다.
2022.02.08 - [엘리스 AI 트랙/데이터 분석 스터디] - [데이터 분석 스터디/항공사 고객 만족도 예측] 항공사 고객 만족도 예측 EDA
[데이터 분석 스터디/항공사 고객 만족도 예측] 항공사 고객 만족도 예측 EDA
https://www.kaggle.com/deltasierra452/airline-pax-satisfaction-survey Airline Passenger Satisfaction Predictive Analysis Airline_pax_satisfaction_survey www.kaggle.com 항공사 고객 만족도 예측 대회..
wnstjrdl.tistory.com
개발환경은 google colab이며 자세한 코드는 포스팅 끝 github주소를 첨부하겠습니다.
1. 추가 EDA
이전 포스팅에서 상관관계 시각화를 통해 여러 특징들 사이의 상관관계와 target과의 상관관계를 알아봤는데 상관계수 Histogram을 살펴보면서 새로운 사실을 알 수 있었다.
위 상관계수를 보면 Depature Delay in Minutes와 Arrival Delay in Minutes인 출발 시간과 도착시간을 주목해보자.
상식적으로 출발시간이 지연되면 당연히 도착시간도 지연된다. departure Delay in Minutes와 Arrival Delay in Minutes은 이 특징을 둘 다 가지고 있다.
상관계수를 보면 0.98로 아주 높은 상관계수를 가지고 있다. 이것이 과연 좋은 값일까?
<다중 공선성>에 따르면 독립변수 즉, target이 아닌 특징들에 대하여 서로 독립적인 관계여야 한다.
하지만 위 특징은 서로 독립적인 관계가 아니고 거의 하나로 움직이는데 주로 상관계수가 0.7이상일 때 다중 공선성이 나타난다고 한다.
0.7 이상의 쌍이 하나 더 존재하는데 Food and drink와 Seat confort인데, 편안한 좌석과 기내식의 상관계수가 높은 것으로 판단된다.
다중 공선성을 제거하기 위해 target과의 상관계수가 낮은 특징들을 제거한다.
- departure Delay in Minutes & Arrival Delay in Minutes : target과의 상관관계(0.1, 0.01)
- target과의 상관관계가 더 낮은 Depature Delay in Minutes 제거
- Food and drink & Seat confort : (0.15, 0.27)
- target과의 상관관계가 더 낮은 Food and drink 제거
data.drop('Departure Delay in Minutes', axis = 1, inplace = True)
data.drop('Food and drink', axis = 1, inplace = True)
test.drop('Departure Delay in Minutes', axis = 1, inplace = True)
test.drop('Food and drink', axis = 1, inplace = True)
2. 이상치 확인
data.plot(kind="box", subplots=True, layout=(5,5), figsize=(15,21))
plt.show()
Arrival Delay in Minutes / Checkin service / Flight Distance에 대한 이상치가 많다.
성능 향상을 위하여 이상치를 제거하기 전에 이상치 인덱스를 뽑아보자
# Numpy를 이용하여 이상치(outlier)를 구하는 함수
def outliers_iqr(data):
q1, q3 = np.percentile(data, [25, 75])
# 넘파이의 값을 퍼센트로 표시해주는 함수
iqr = q3 - q1
lower_bound = q1 - (iqr * 1.5)
upper_bound = q3 + (iqr * 1.5)
return np.where((data > upper_bound) | (data < lower_bound))ArrayDelay_index = outliers_iqr(data['Arrival Delay in Minutes'])[0]
Checkin_index = outliers_iqr(data['Checkin service'])[0]
FlightDistance_index = outliers_iqr(data['Flight Distance'])[0]Checkin_index # 500개 이상FlightDistance_index # 100개 이상ArrayDelay_index # 500개 이상이상치 데이터들을 삭제하려고 했으나 생각보다 이상치 데이터들이 많아서 삭제한다면 학습에 문제 될 것으로 판단
제거가 아닌 평균값으로 대치
data.loc[ArrayDelay_index, 'Arrival Delay in Minutes'] = data['Arrival Delay in Minutes'].mean()
data.loc[FlightDistance_index, 'Flight Distance'] = data['Flight Distance'].mean()
data.loc[Checkin_index, 'Checkin service'] = data['Checkin service'].mean()data.plot(kind="box", subplots=True, layout=(5,5), figsize=(15,21))
plt.show()
이상치 수정 완료
테스트 셋에도 적용 필요하다.
ArrivalDelay_index = outliers_iqr(test['Arrival Delay in Minutes'])[0]
FlightDistance_index = outliers_iqr(test['Flight Distance'])[0]
GarageArea_index = outliers_iqr(test['Checkin service'])[0]
test.loc[ArrivalDelay_index, 'Arrival Delay in Minutes'] = test['Arrival Delay in Minutes'].mean()
test.loc[FlightDistance_index, 'Flight Distance'] = test['Flight Distance'].mean()
test.loc[GarageArea_index, 'Checkin service'] = test['Checkin service'].mean()3. 데이터 전처리
낮은 상관계수 특징 제거
- 특징이 많을수록 과적합이 일어날 수 있기 때문에 상관계수가 가장 낮은 특징 3개를 제거한다.
# 데이터 셋
data.drop('Departure/Arrival time convenient', axis = 1, inplace = True)
data.drop('Gate location', axis = 1, inplace = True)
data.drop('Flight Distance', axis = 1, inplace = True)
# 테스트 셋
test.drop('Departure/Arrival time convenient', axis = 1, inplace = True)
test.drop('Gate location', axis = 1, inplace = True)
test.drop('Flight Distance', axis = 1, inplace = True)data.shape, test.shape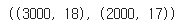
범주형 데이터 숫자화 하기
# 데이터 셋
data[data.columns[data.dtypes=='O']] = data[data.columns[data.dtypes=='O']].astype(str).apply(LabelEncoder().fit_transform)
# 테스트 셋
test[test.columns[test.dtypes=='O']] = test[test.columns[test.dtypes=='O']].astype(str).apply(LabelEncoder().fit_transform)
data
4. 모델 학습
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from catboost import CatBoostClassifier
from sklearn.ensemble import ExtraTreesClassifierdef ACCURACY(true, pred):
score = np.mean(true==pred)
return score값의 범위 차이가 큰 특징들 age / (Departure Delay in Minutes, Arrival Delay in Minutes)로 인해 진행한 결과와 스케일링하지 않은 결과를 비교하자
from sklearn.model_selection import StratifiedKFold
from sklearn.preprocessing import MinMaxScaler # MinMaxScale 사용
scale_feature = [
'Age',
'Arrival Delay in Minutes'
]
def kfold(model, train, scale = False):
cv_accuracy = []
cv = StratifiedKFold(n_splits=5)
n_iter = 0
for t, v in cv.split(train, train['target']):
train_cv = train.iloc[t] # 훈련용
val_cv = train.iloc[v] # 검증용 분리
train_X = train_cv.drop('target', axis=1)
train_y = train_cv['target']
val_X = val_cv.drop('target', axis=1)
val_y = val_cv['target']
if scale:
scaler = MinMaxScaler()
for feature in scale_feature:
train_X = scaler.fit_transform(train_X)
val_X = scaler.fit_transform(val_X)
model.fit(train_X, train_y)
score = ACCURACY(val_y, model.predict(val_X))
cv_accuracy.append(score)
n_iter += 1
return np.mean(cv_accuracy)스케일링 적용 전
models = [
KNeighborsClassifier(),
LogisticRegression(),
DecisionTreeClassifier(),
RandomForestClassifier(),
GradientBoostingClassifier(),
XGBClassifier(eval_metric='logloss'), # eval_metric='logloss' 버전 경고 문구 제거
LGBMClassifier(),
CatBoostClassifier(silent = True), # silent = True 학습 내용 출력 제거
ExtraTreesClassifier()
]
print('스케일링 적용 전')
for model in models:
print(f'{type(model).__name__} score: {kfold(model, data)}')
스케일링 적용 후
models = [
KNeighborsClassifier(),
LogisticRegression(),
DecisionTreeClassifier(),
RandomForestClassifier(),
GradientBoostingClassifier(),
XGBClassifier(eval_metric='logloss'), # eval_metric='logloss' 버전 경고 문구 제거
LGBMClassifier(),
CatBoostClassifier(silent = True), # silent = True 학습 내용 출력 제거
ExtraTreesClassifier()
]
for model in models:
print(f'{type(model).__name__} score: {kfold(model, data, True)}')
스케일링을 적용한 결과 성능이 더 떨어진 것을 볼 수 있다. 스케일링을 쓰지 말자
5. 모델 앙상블
원본 데이터에서 성능이 좋게 나온 상위 5가지 모델과 5가지 모델의 앙상블 한 결과를 비교하자
# 원본
from sklearn.model_selection import train_test_split
train = data.drop('target', axis=1)
target = data['target']
train_x, val_x, train_y, val_y = train_test_split(train, target, random_state = 42)
model_RFC = RandomForestClassifier().fit(train_x, train_y)
model_XGB = XGBClassifier(eval_metric='logloss').fit(train_x, train_y)
model_LGBM = LGBMClassifier().fit(train_x, train_y)
model_CAT = CatBoostClassifier(silent = True).fit(train_x, train_y)
model_EXTRA = ExtraTreesClassifier().fit(train_x, train_y)
pred_RFC = model_RFC.predict(val_x)
pred_XGB = model_XGB.predict(val_x)
pred_LGBM = model_LGBM.predict(val_x)
pred_CAT = model_CAT.predict(val_x)
pred_EXTRA = model_EXTRA.predict(val_x)
print('RFC:', ACCURACY(val_y, pred_RFC))
print('XGB:', ACCURACY(val_y, pred_XGB))
print('LGBM:', ACCURACY(val_y, pred_LGBM))
print('CAT:', ACCURACY(val_y, pred_CAT))
print('EXTRA:', ACCURACY(val_y, pred_EXTRA))
# 앙상블
predict = np.zeros(pred_RFC.shape)
predict = (pred_LGBM + pred_XGB + pred_CAT + pred_RFC + pred_EXTRA) / 5
predict[predict > 0.5] = 1
predict[predict < 0.5] = 0
predict
ACCURACY(val_y, predict)
앙상블은 하드 보팅 진행(소프트 보팅 연구 -ing)
6. 모델 튜닝
최종적으로 적용 전 모델 튜닝을 적용할 예정인데, gridSearchCV를 통해 최적의 파라미터를 찾아보자.(optuna는 추후에 연구 -ing)
from sklearn.model_selection import KFold, GridSearchCVRandomForest
params = { 'n_estimators' : [10, 100, 1000],
'max_depth' : [6, 8, 10, 12],
'min_samples_leaf' : [8, 12, 18],
'min_samples_split' : [8, 16, 20]
}model_RFC = RandomForestClassifier()
grid_cv_RFC = GridSearchCV(model_RFC, param_grid = params, cv=5, n_jobs = -1)
grid_cv_RFC.fit(train, target)
print('최적 하이퍼 파라미터: ', grid_cv_RFC.best_params_)
print('최고 예측 정확도: {:.4f}'.format(grid_cv_RFC.best_score_))
XGBClassifier
참고 사이트 : https://m.blog.naver.com/PostView.naverisHttpsRedirect=true&blogId=gustn3964&logNo=221431933811
파이썬 GridSearchCV() 사용법
제가 알고있는 지식이 얕아서 대표적으로 설명하자면.. 밑에 올렸던 XGBoost 사용법을 보시면 파라미터...
blog.naver.com
model_XGB = XGBClassifier(eval_metric='logloss', silent = True)
param_grid={'booster' :['gbtree'],
'silent':[True],
'max_depth':[5,6,8],
'min_child_weight':[1,3,5],
'gamma':[0,1,2,3],
'nthread':[4],
'colsample_bytree':[0.5,0.8],
'colsample_bylevel':[0.9],
'n_estimators':[50],
'objective':['binary:logistic'],
'random_state':[2]}
grid_cv_XGB=GridSearchCV(model_XGB, param_grid=param_grid, cv=5 , n_jobs=-1)
grid_cv_XGB.fit(train, target)
print('최적 하이퍼 파라미터: ', grid_cv_XGB.best_params_)
print('최고 예측 정확도: {:.4f}'.format(grid_cv_XGB.best_score_))
LGBMClassifier
참고 사이트 : https://www.kaggle.com/bitit1994/parameter-grid-search-lgbm-with-scikit-learn
Parameter grid search LGBM with scikit-learn
Explore and run machine learning code with Kaggle Notebooks | Using data from WSDM - KKBox's Music Recommendation Challenge
www.kaggle.com
model_LGBM = LGBMClassifier()
gridParams = {
'learning_rate': [0.005, 0.01],
'n_estimators': [100, 500, 1000],
'num_leaves': [12, 16, 20], # large num_leaves helps improve accuracy but might lead to over-fitting
'boosting_type' : ['dart'], # for better accuracy -> try dart
'objective' : ['binary'],
'max_bin':[300, 600], # large max_bin helps improve accuracy but might slow down training progress
}
grid_cv_LGBM = GridSearchCV(model_LGBM, param_grid=gridParams, cv=3 , n_jobs=-1)
grid_cv_LGBM.fit(train, target)
print('최적 하이퍼 파라미터: ', grid_cv_LGBM.best_params_)
print('최고 예측 정확도: {:.4f}'.format(grid_cv_LGBM.best_score_))
CatBoostClassifier
참고 사이트 : https://catboost.ai/en/docs/concepts/python-reference_catboost_grid_search
grid_search
A simple grid search over specified parameter values for a model. Note. After searching, the model is trained and ready to use. Method call format.
catboost.ai
model_CAT = CatBoostClassifier(silent = True)
grid = {'learning_rate': [0.03, 0.1],
'depth': [4, 6, 10],
'l2_leaf_reg': [1, 3, 5, 7, 9]}
grid_cv_CAT = GridSearchCV(model_CAT, param_grid=grid, cv=3 , n_jobs=-1)
grid_cv_CAT.fit(train, target)
print('최적 하이퍼 파라미터: ', grid_cv_CAT.best_params_)
print('최고 예측 정확도: {:.4f}'.format(grid_cv_CAT.best_score_))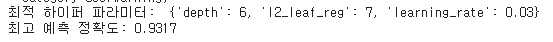
best_model_XGB = grid_cv_XGB.best_estimator_ # 최적 하이퍼 파라메터로 설정, 학습된 모델 저장
best_model_RFC = grid_cv_RFC.best_estimator_
best_model_LGBM = grid_cv_RFC.best_estimator_
best_model_CAT = grid_cv_CAT.best_estimator_
best_model_EXTRA = ExtraTreesClassifier(n_estimators = 1000).fit(train, target)
7. 제출
pred_XGB = best_model_XGB.predict(test)
pred_RFC = best_model_RFC.predict(test)
pred_LGBM = best_model_LGBM.predict(test)
pred_CAT = best_model_CAT.predict(test)
pred_EXTRA = best_model_EXTRA.predict(test)
predict = ( pred_XGB + pred_LGBM + pred_CAT) / 3 # Hard voting
predict[predict > 0.5] = 1
predict[predict < 0.5] = 0submission = pd.read_csv('submission/sample_submission.csv')
submissionsubmission.to_csv('submission/submission_XGB_LGBM_CAT.csv', index=False)
| pred_XGB + pred_LGBM + pred_CAT | pred_CAT |
( pred_RFC + pred_XGB + pred_LGBM + pred_CAT + pred_EXTRA)
|
|
| 점수 | 0.93 | 0.93 | 0.924 |
* 항공사 고객 만족도 예측의 전체적인 머신러닝 파이프라인에 대해 포스팅 했습니다.
* 아직 부족한 점이 많고, 실험해봐야 할 조건들(soft voting, scale, 0의 의미 등)도 많아서 해봐야 할 거 같습니다.
* 현재까지는 xgb, lgbm, cat 앙상블 한 모델과 cat 단일 모델의 성능이 유사한 것으로 판명되었습니다.
* 다음 포스팅은 부분적인 수정을 더한 성능 향상을 목표로 하는 포스팅을 하겠습니다. 감사합니다.
GitHub - JunSeokCheon/Airline-Customer-Satisfaction-Prediction
Contribute to JunSeokCheon/Airline-Customer-Satisfaction-Prediction development by creating an account on GitHub.
github.com
'Data Projects > mini 데이터 분석 프로젝트' 카테고리의 다른 글
| [데이터 분석 스터디/항공사 고객 만족도 예측] 항공사 고객 만족도 예측 EDA (0) | 2022.02.08 |
|---|---|
| [데이터 분석 스터디] 03 넷플릭스 시청 데이터로 알아보는 데이터형 변환 (0) | 2022.01.29 |
| [데이터 분석 스터디] 02 영어 단어 모음으로 시작하는 텍스트 파일 분석 (0) | 2022.01.29 |
| [데이터 분석 스터디] 01 트럼프 대통령 트윗으로 시작하는 데이터 처리 (0) | 2022.01.28 |




댓글