- 이번 프로젝트는 kaggle에서 제공하는 데이터셋인 eCommerce 웹 로그 데이터 분석 프로젝트이다.
eCommerce behavior data from multi category store
This dataset contains 285 million users' events from eCommerce website
www.kaggle.com
1. 데이터 전처리
2. 데이터 분석 & 시각화
3. 데이터 모델링
해당 포스팅은 데이터 전처리 과정이다.
데이터 load & import
필요한 데이터와 라이브러리를 import 한다. 데이터는 위 사이트에서 2019-oct, 2019-nov 중 2019-oct 데이터를 사용한다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime, timedelta
%matplotlib inline
ecommerce_df = pd.read_csv("2019-Oct.csv")
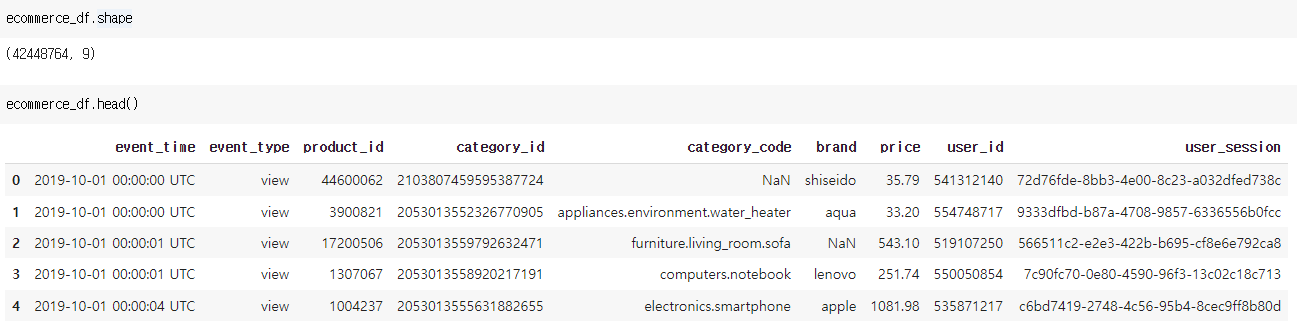
데이터 가볍게 살펴보기
4200만 개 데이터와 9개의 칼럼(event_time, event_type, product_id, category_id, category_code, brand, price, user_id, user_session)으로 구성되어 있다.
결측 값(NaN)과 텍스트 통일 등 여러 가지 전처리를 확인하자.
칼럼들에 대한 데이터 타입을 보면 event_time에 대한 처리가 필요할 것으로 보인다.

결측 값 제거
각 칼럼들을 상세히 알아보기 전에 데이터 수가 많기 때문에 결측 값(NaN)이 있는 데이터는 삭제하자.
15,888,144개의 결측 값이 제거되었다.

event_time
데이터의 time은 2019년 10월 데이터이다.
데이터의 timezone이 UTC 기준이므로 KST로 변경하자. (KST는 UTC보다 9시간 빠르다)

UTC -> KST 변경 방법
1. event_time에서 UTC 문자열을 제외한 date 데이터만 추출해서 리스트에 저장한다.
utc_list = []
for date in aft_ecommerce_df['event_time']:
utc_list.append(date[:19])
2. convert_kst 함수에서 9시간을 더해서 utc -> kst로 변환한다.
def convert_kst(utc_string):
utc_dt = datetime.strptime(utc_string, '%Y-%m-%d %H:%M:%S')
kst_dt = utc_dt + timedelta(hours=9)
str_datetime = kst_dt.strftime('%Y-%m-%d %H:%M:%S')
return str_datetime
3. 새로운 칼럼(kst_time)을 만들어서 변환한 데이터를 추가한다.
kst_list = []
for utc in utc_list:
kst_list.append(convert_kst(utc))
aft_ecommerce_df['kst_time'] = pd.DataFrame(kst_list)
4. 필요 없어진 event_time을 삭제한다.
aft_ecommerce_df = aft_ecommerce_df.drop(['event_time'], axis = 1)
aft_ecommerce_df.head()
5. kst_time의 데이터 타입을 datetime으로 변환한다.
aft_ecommerce_df['kst_time'] = pd.to_datetime(aft_ecommerce_df['kst_time'])
aft_ecommerce_df.info()

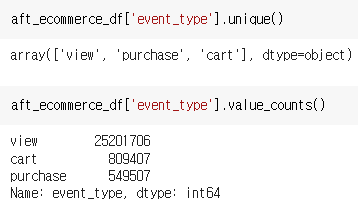
event_type
event_type에는 view, purchase, cart가 존재하며, 비율은 view가 압도적으로 높다.
시각화하여 표현하면 아래와 같다.
labels = ['view', 'cart','purchase']
size = aft_ecommerce_df['event_type'].value_counts()
colors = ['yellowgreen', 'lightskyblue','lightcoral']
explode = [0, 0.1,0.1]
plt.rcParams['figure.figsize'] = (8, 8)
plt.pie(size, colors = colors, explode = explode, labels = labels, shadow = True, autopct = '%.2f%%')
plt.title('Event_Type', fontsize = 20)
plt.axis('off')
plt.legend()
plt.show()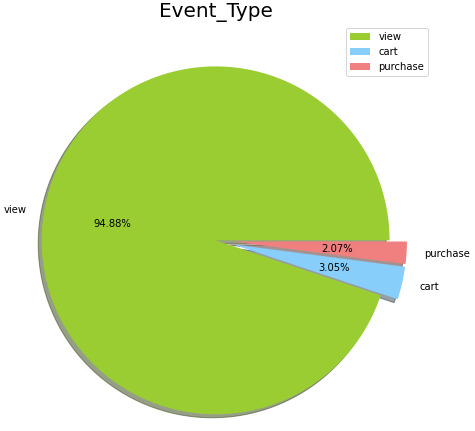
product_id, categort_id, category_code, user_id, user_session
1. product_id, category_id, category_code, brand는 같은 양상을 보이지만 price는 같은 제품이라도 날짜에 따른 가격 차이가 존재한다.
2. user_id, user_session은 같은 양상을 보이는 경우도 있고, user_id가 같더라도 user_session이 다른 경우도 있다.


brand
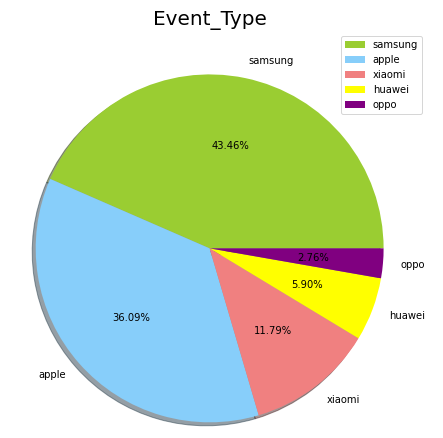
많은 수의 브랜드가 존재하고, event_type이 purchase인 데이터를 보면 제품의 브랜드에 따른 판매량을 볼 수 있다.

purchase = aft_ecommerce_df.loc[aft_ecommerce_df['event_type'] == "purchase"]
top_sell_brand = purchase.groupby('brand')['brand'].agg(['count']).sort_values('count', ascending=False)
top_sell_brand.head(10)
판매량 순위를 보면 위와 같고, 그래프로 top 5 brand를 표현하면 삼성, apple, xiaomi, huawei, oppo로 나타난다.
price
가격은 0.88달러부터 2574달러까지 다양하게 분포되어 있다.
최소 가격 제품은 ritmix사의 헤드폰이고, 최대 가격 제품은 rado사의 시계이다.

마무리
이번 포스팅에서 eCommerce 웹 로그 데이터의 전처리와 각 칼럼들에 대해 간단하게 알아봤습니다.
다음 포스팅부터는 로그 데이터에 대한 분석과 시각화를 진행하겠습니다. 해당 프로젝트는 아래 github에 상세히 정리가 되어 있어서 많은 관심 부탁드립니다. 개인으로 진행한 프로젝트라 정확하지 않을 수 있는 점 양해 부탁드립니다.
https://github.com/JunSeokCheon/eCommerce_weblog_analysis
GitHub - JunSeokCheon/eCommerce_weblog_analysis
Contribute to JunSeokCheon/eCommerce_weblog_analysis development by creating an account on GitHub.
github.com
'Data Projects > ecommerce 로그 데이터 분석 프로젝트' 카테고리의 다른 글
| [ecommerce 웹 로그 분석] 4. XGBoost 사용한 고객 행동 예측 모델 (0) | 2022.06.28 |
|---|---|
| [ecommerce 웹 로그 분석] 3. 데이터 분석 & 시각화 (2) (0) | 2022.06.24 |
| [ecommerce 웹 로그 분석] 2. 데이터 분석 & 시각화 (1) (0) | 2022.06.23 |



댓글